https://hyen4110.tistory.com/88
[Pytorch][BERT] 버트 소스코드 이해_② BertConfig
[Pytorch][BERT] 버트 소스코드 이해 목차 BERT 📑 BERT Config 👀 📑 BERT Tokenizer 📑 BERT Model 📑 BERT Input 📑 BERT Output 📑 BERT Embedding 📑 BERT Pooler 📑 BERT Enocder 📑 BERT Layer 📑 BERT SelfAttention 📑 BERT SelfO
hyen4110.tistory.com
BERT 소스 코드는 위 링크에서 확인해볼 수 있다.
NLP 분야에서 embedding 과정을 거치는 데, 사람이 쓰는 자연어를 기계가 이해할 수 있는 형태(숫자나 벡터)로 바꾸는 과정 전체를 임베딩이라고 한다.
즉, 임베딩은
1. 단어/문장 간 관련도 계산
2. 단어와 단어 사이의 의미적/문법적 정보 함축(단어 유추 평가)
3. 전이 학습(Transfer Learning, 좋은 임베딩을 딥러닝 모델 입력 값으로 사용하는 것)
BERT(또는 Bidirectional Encoder Representations from Transformers)는 자연어 처리(Natural Language Processing, NLP) 분야에서 주목받는 모델 중 하나이다.
여러 층의 Transformer 어텐션 메커니즘을 사용하여 양방향으로 문맥을 파악하고, 대규모 텍스트 코퍼스에서 사전 훈련된 언어 표현을 학습하는 것이 특징이다.
1. 양방향 학습 모델(Bidirectional Learning): BERT는 문장의 양쪽 방향(앞뒤)으로 정보를 고려하여 문맥을 이해하는 데에 강점이 있습니다. 이는 단방향 모델보다 높은 성능을 보이는 경우가 많습니다.
2. Pre-trained 모델: BERT는 방대한 양의 텍스트 코퍼스(3.3억 단어)를 사용하여 사전 훈련되었습니다. 이는 BERT가 풍부한 문맥 정보를 학습하고, 이를 통해 다양한 자연어 처리 작업에서 전이 학습(transfer learning)을 수행할 수 있게 해줍니다.
3. 라벨 자동 생성 및 준지도학습: BERT는 대규모 데이터셋에서 자동으로 라벨을 생성하고, 일부는 라벨이 제공되지 않은 준지도학습(semi-supervised learning) 방식을 사용합니다. 이는 다양한 도메인 및 작업에서 유연하게 적용할 수 있도록 모델을 일반화시키는 데 도움이 됩니다.
4. 단어 의미 표현: BERT의 임베딩 성능은 단어의 의미를 효과적으로 표현할 수 있도록 설계되었습니다. 이를 통해 모델은 문장이나 문단의 의미를 더 잘 이해하고 표현할 수 있습니다.
5. 범용 언어 모델: BERT는 다양한 자연어 처리 작업에서 우수한 성능을 보이는 범용 언어 모델로 평가됩니다. 문장 이해, 문장 생성, 기계 번역, 질문 응답 등 다양한 작업에 적용 가능합니다.
= 즉, BERT는 전이학습 모델이자 사전 학습 모델이다.
대용량의 데이터를 직접 학습시키기 위해서는 매우 많은 자원과 시간이 필요하지만 BERT 모델은 기본적으로 대량의 단어 임베딩 등에 대해 사전 학습이 되어 있는 모델을 제공하기 때문에 상대적으로 적은 자원만으로도 충분히 자연어 처리의 여러 일을 수행할 수 있다.
BERT의 동작 과정
1) input
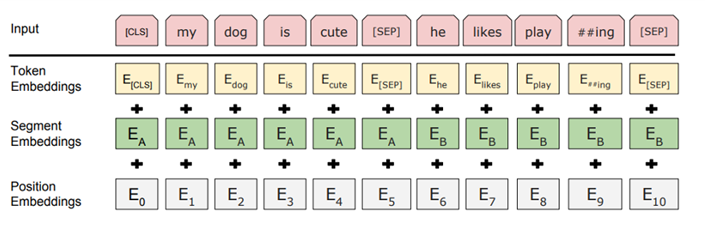
BERT의 input representation은 그림과 같이 세 가지 임베딩 값의 합으로 구성된다.
1. Token Embedding (토큰 임베딩):
- BERT는 입력 문장을 토큰 단위로 분할합니다. 각 토큰은 사전 훈련된 임베딩 벡터로 매핑됩니다. 이 임베딩 벡터는 모델이 단어의 의미를 이해하고 표현할 수 있도록 합니다. 토큰 임베딩은 주어진 토큰이 어떤 단어를 나타내는지에 대한 정보를 담고 있습니다.
- Token Embeddings는 Word piece 임베딩 방식을 사용, Word Piece 임베딩은 자주 등장하면서 가장 긴 길이의 sub-word을 하나의 단위로 만듦, 자주 등장하는 단어(sub-word)는 그 자체가 단위가 되고, 자주 등장하지 않는 단어(rare word)는 더 작은 sub-word로 쪼개어진다.
2. Segment Embedding (세그먼트 임베딩):
- BERT는 두 문장을 함께 처리할 수 있습니다. 예를 들어, 질문과 답변이 같이 주어진 경우 이를 하나의 입력으로 처리할 수 있습니다. 세그먼트 임베딩은 각 토큰이 어느 문장에 속하는지를 나타냅니다. 하나의 문장일 경우에는 모두 같은 세그먼트 임베딩이 부여되고, 두 번째 문장이면 다른 값을 갖습니다.
3. Position Embedding (포지션 임베딩):
- BERT는 입력 시퀀스의 토큰들을 순서대로 처리합니다. 그러나 트랜스포머의 어텐션 메커니즘은 입력의 상대적 위치에 대한 정보를 갖지 않습니다. 이를 보완하기 위해 포지션 임베딩이 도입됩니다. 각 토큰의 위치 정보를 인코딩하는 임베딩 벡터가 추가됩니다. 이를 통해 모델은 단어의 상대적인 위치에 대한 정보를 활용할 수 있습니다.
이러한 임베딩들이 결합되어 BERT의 입력 표현이 구성됩니다. 토큰, 세그먼트, 포지션 임베딩이 모두 합쳐져 각 토큰의 최종 입력 임베딩 벡터가 생성됩니다.
2) 사전 훈련(pre-training) 단계

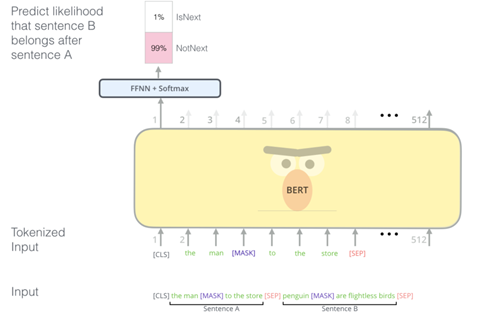
BERT는 대규모 텍스트 코퍼스에서 사전 훈련됩니다. 이 과정에서 모델은 언어의 문맥적 이해와 단어 간의 관계를 학습합니다. 아래는 BERT의 사전 훈련 단계의 주요 과정입니다:
- 양방향 어텐션 메커니즘: BERT는 Transformer의 어텐션 메커니즘을 사용하여 각 단어가 문장의 다른 부분과 어떻게 상호 작용하는지를 학습합니다. 이 어텐션 메커니즘은 양방향으로 작동하여 단어의 왼쪽과 오른쪽 문맥을 동시에 고려할 수 있도록 합니다.
- 마스크 언어 모델(Masked Language Model, MLM): BERT는 입력 문장에서 일부 단어를 랜덤하게 마스킹한 후, 마스킹된 단어를 예측하는 MLM 작업을 수행합니다. 이를 통해 모델은 문맥 속에서 빠진 단어를 예측하고, 이를 통해 단어 간의 상호 작용을 학습합니다. = Masked Language Model, 입력 문장에서 임의로 토큰을 버리고(Mask), 그 토큰을 맞추는 방식으로 학습을 진행
- 다음 문장 예측(Next Sentence Prediction, NSP): BERT는 두 문장의 쌍을 입력으로 받아, 두 번째 문장이 첫 번째 문장과 연결되는지를 예측하는 NSP 작업을 수행합니다. 이를 통해 모델은 문장 간의 관계를 학습하게 됩니다. = 두 문장을 주고 순서를 예측하는 방식으로, 문장 간 관련성을 고려하며 학습을 진행
3) Transfer Learning
- 학습된 언어모델을 전이학습시켜 실제 NLP 수행하는 과정

4) 파인 튜닝(fine-tuning) 단계

거대 Encoder가 입력 문장들을 임베딩하여 언어를 모델링하는 Pre-training 과정과
이를 fine-tuning하여 여러 자연어 처리 Task를 수행하는 과정입니다.
사전 훈련된 BERT 모델은 특정 자연어 처리 작업을 위해 파인 튜닝됩니다. 파인 튜닝은 특정 작업에 맞게 모델을 조정하는 과정입니다. 주요 단계는 다음과 같습니다:
- 입력 인코딩: 특정 작업에 맞는 입력 형식으로 문장이 인코딩됩니다. 이 때, BERT는 문장의 각 단어를 벡터로 변환하고, segment embeddings 및 position embeddings을 추가하여 문맥과 문장 구조를 고려합니다.
- 출력 계층 추가: 특정 작업에 맞게 출력 계층이 추가되거나 조정됩니다. 예를 들어, 감정 분류 작업을 위한 출력 노드나, 질문 응답 작업을 위한 시작 및 종료 지점을 예측하기 위한 노드 등이 추가될 수 있습니다.
- 손실 함수 및 역전파: 주어진 작업에 맞는 손실 함수를 정의하고, 역전파를 통해 모델을 학습시킵니다. 파인 튜닝은 사전 훈련된 가중치를 초기값으로 사용하면서 특정 작업에 맞게 모델을 조정하는 과정이므로 적은 양의 데이터로도 효과적인 학습이 가능합니다.
+ Transformer기반의 BERT
BERT는 MLM과 NSP를 위해 Transformer을 기반으로 구성
기존 인코더-디코더 모델과 달리 Transformer는 CNN 및 RNN을 사용하지 않고 self-attention 개념을 도입
BERT는 Transformer의 인코더-디코더 중 인코더만 사용

1) BERT의 MLM(Masked Language Model):
- 임의의 토큰 마스킹: 입력 시퀀스에서 15%의 토큰을 임의로 선택하여 [MASK] 토큰으로 바꿉니다.
- 마스킹된 토큰 예측: [MASK]로 바뀐 토큰들 중에서 80%는 [MASK]로 바꾸고, 10%는 무작위 단어로 바꾸며, 10%는 그대로 둡니다.
- 좌우 문맥 활용: 이렇게 마스킹된 토큰들을 Transformer 구조에 입력으로 넣고, 주변 단어의 맥락을 활용하여 [MASK] 토큰들을 예측합니다.
- 전체 문장 예측과의 차이: 이전의 사전학습 언어 모델은 주어진 문장 전체를 예측하는 방식이었다면, MLM은 일부 토큰만을 예측하여 모델이 언어의 맥락을 잘 이해할 수 있도록 합니다.
- Fine-tuning에서의 활용: [MASK] 토큰은 사전학습에만 사용되며, fine-tuning 단계에서는 사용되지 않습니다.
이러한 MLM 작업을 통해 BERT는 문장 내의 단어 간 상호 작용을 이해하고, 문맥을 파악하는 능력을 갖춤
2) BERT의 NSP(Next Sentence Prediction):
- 두 문장의 관계 예측: NSP는 두 문장의 관계를 이해하기 위해 사용됩니다. 주어진 두 문장 중에서 두 번째 문장이 첫 번째 문장 다음에 올지 여부를 예측
- 문장 쌍 생성: 두 문장의 쌍을 생성하고, 이를 BERT에 입력으로 제공
- 이진 분류 문제: NSP는 이진 분류 문제로, 주어진 두 문장이 연속된 문장인지 아닌지를 예측
- Fine-tuning에서의 활용: NSP는 모델이 문장 간의 관계를 학습하는 데 도움을 주며, fine-tuning 단계에서는 특정 작업에 맞게 모델을 조정하는 데 활용됩니다.
이러한 NSP 작업을 통해 BERT는 문장 간의 의미적인 관계를 파악하고, 문맥을 이해하는 능력을 향상시킵니다.

- 위의 input representation 과정에서 살펴본 것처럼 BERT는 [SEP] 특수 토큰으로 문장을 분리
- 학습 중에 모델에 입력으로 두 개의 문장이 동시에 제공
- 50%의 경우 실제 두 번째 문장이 첫 번째 문장 뒤에 오고 50%는 전체 말뭉치에서 나오는 임의의 문장, 그런 다음 BERT는 임의의 문장이 첫 번째 문장에서 분리된다는 가정 하에 두 번째 문장이 임의의 문장인 여부를 예측
- 이를 위해 완전한 입력 시퀀스는 Transformer 기반 모델을 거치며, [CLS] 토큰의 출력은 간단한 분류 계층을 사용하여 2x1 모양의 벡터로 변환됩니다.
- IsNext-Label은 softmax를 사용하여 할당, BERT는 손실 함수를 최소화하기 위해 MLM과 NSP을 함께 학습
BERT 모델은 크게 두 가지 버전으로 나뉩니다: BERT-base와 BERT-large. 이 두 모델은 모델 크기와 파라미터 수에서 차이가 있으며, 주로 모델의 용량과 성능 간의 트레이드오프를 다룹니다.
1. BERT-base:
- 모델 크기: BERT-base는 상대적으로 작은 모델로, 12개의 Transformer 층을 가지고 있습니다.
- 파라미터 수: 대략 1억 1천만 개 정도의 파라미터를 갖고 있습니다.
- 사용 사례: BERT-base는 다양한 자연어 처리 작업에 효과적으로 사용될 수 있으며, 작은 메모리 환경에서도 비교적 경제적으로 사용할 수 있습니다.
2. BERT-large:
- 모델 크기: BERT-large는 큰 모델로, 24개의 Transformer 층을 가지고 있습니다.
- 파라미터 수: 대략 3억 4천만 개 정도의 파라미터를 갖고 있습니다. BERT-base에 비해 파라미터 수가 많아집니다.
- 사용 사례: BERT-large는 BERT-base보다 더 많은 파라미터를 갖고 있어서 더 복잡한 모델을 표현할 수 있습니다. 이는 특히 대규모 데이터셋에서 성능을 높이고자 할 때 사용됩니다. 그러나 더 많은 파라미터는 더 많은 계산 리소스와 메모리를 필요로 하므로, 환경 및 요구 사항에 따라 선택되어야 합니다.
이러한 두 버전의 BERT 모델은 다양한 자연어 처리 작업에서 효과적으로 사용됩니다. 모델의 크기가 커질수록 더 많은 파라미터를 학습할 수 있어서 더 복잡한 패턴과 특징을 감지할 수 있지만, 그에 따라 더 많은 계산 리소스와 메모리가 필요합니다. 선택은 주어진 작업과 환경에 따라 달라집니다.

'AI HW study > AI - NLP' 카테고리의 다른 글
| Part 7 - Chapter 1. Introduction to NLP (0) | 2024.02.01 |
|---|---|
| Part 1 CH 02-01. 선수 지식 - 자료구조 (0) | 2024.01.29 |
| GitHub 사용법을 알아봅시다 (0) | 2024.01.22 |
| PyTorch for Deep Learning & Machine Learning – Full Course (0) | 2024.01.08 |
| AI공부 사이트 ( + Bert + ResNet) (0) | 2024.01.04 |

